
We previously explored Supervised Learning as a sub-category of Machine Learning, now we will delve into Unsupervised Learning.
Unlike in supervised learning, unsupervised learning does not rely on labeled data; instead, it explores the inherent structure of the data without explicit guidance on what to look for. Unsupervised learning is a type of machine learning where the algorithm (model) learns from test data that has not been labeled, classified or categorized. The absence of labeled outcomes makes unsupervised learning particularly useful in scenarios where obtaining labeled data is impractical or expensive.
There are three main applications of unsupervised learning:
Clustering: A data mining technique which groups unlabeled data based on their similarities or differences. The primary goal here is to uncover hidden structures within the data, identifying patterns that may not be immediately apparent, without explicit guidance. Imagine a child that sees a bright yellow fruit and believes that it would be as tasty as it looks, but soon finds outs that lemons are sour. The next time that child encounters a fruit of same nature, they will be reminded of the previous experience. Similarly, clustering can be used to observe and group customers with similar purchasing behaviors, helping businesses tailor marketing strategies.
Association: A rule-based method for finding relationships or associations between variables in a given large dataset. In this method, no predefined outcome or labeled data is provided, the algorithm just explores the data to find rules that describe relationships between variables. The most common application of association rule is in the market basket analysis – a data analysis technique used in retail and other industries to discover associations between products or services that are frequently purchased together. An example of this can be seen in Amazon’s “Customers Who Bought This Item Also Bought” or Spotify’s “Discover Weekly” playlist.
Dimensionality Reduction: While more data generally yields more accurate results, it can impact the performance of machine learning algorithms (e.g. overfitting) and make it difficult to visualize datasets. Dimensionality reduction is a technique that simplifies complex datasets by reducing the number of features while retaining essential information, making it more manageable for analysis and visualization. Imagine a scenario where a facial recognition system needs to process and identify individuals based on images. Each image contains a high number of pixels, making it a high-dimensional dataset. A reduction technique like PCA can be applied to the dataset of facial images to identify the principal components.
Unsupervised learning holds immense potential; however, it comes with some challenges. Evaluating the performance of unsupervised algorithms can be subjective, as there is no explicit metric to measure accuracy.
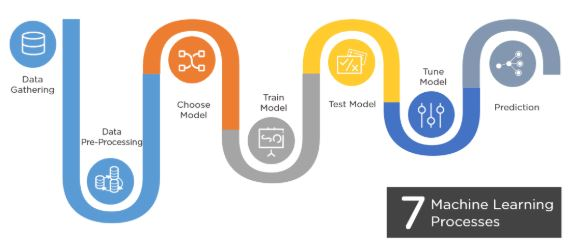
In conclusion, machine learning has fast become an integral part of our daily lives, impacting various aspects and enhancing our experiences in ways that we might not always be aware of. It’s reach extends from personalized recommendations on streaming services and online shopping platforms to optimizing the functionality of smart devices within our homes. Beyond that, it has significantly contributed in medical diagnostics capabilities and revolutionized the automotive sector with the advent of self-driving cars. The systematic application of machine learning unfolds through various steps, ultimately leading to informed predictions and solutions, as shown below.


 CRISIS COMMUNICATION
CRISIS COMMUNICATION